ACS Persistenceby Bob Donald (bdonald@arsdigita.com.com) Submitted on: 2001-08-22
ArsDigita : ArsDigita Systems Journal : One article
Introduction Before delving into persistence, let's look at a brief history of database access in the software industry to provide common ground in understanding where we are and how we got here. Data Access, the beginning
For years, many architects and system developers have not given this issue the attention it rightly deserves. The most common approach is to write code that talks directly to the database API provided in your environment. In the early days of SQL databases, your only option was to use the database API provided by the database vendor, such as Oracle's OCI (Oracle Call Interface). This solved the initial need to enable your application for a particular database. However, your application was then tied to that database. You could not easily support another database, if at all, due to its different database-specific APIs, as well as the prohibitive cost. Data Access, improvements
Data Access, remaining shortcomings
Later, Microsoft provided OLE DB, followed by ADO. Each simplified the API by providing objects for creating connections and statements, but the issue of SQL residing in your application code remained. The corresponding common database API in the Java world is JDBC (Java Database Connectivity) and it has similar issues to those of ODBC. So what did developers do? Many good developers created a library of SQL statements in their code and provided a public API for the rest of the application developers to call. This encapsulated all the database calls into a central location that could be maintained and updated appropriately as the application matured. This does not solve the problem of having to update the code when the database schema changes, but it makes it much easier to manage. After you have developed several applications or systems following this approach, you will begin to see the problem it creates. As your application matures and additional features are added over time, your application accesses the same database table from several locations in your code. The application modifies the same table in several different places in your application, sometimes in different ways. This can make it very difficult to track down and isolate problems in your code. If I were to guess why people continue to develop in this way, I would say that most applications today start with a simple prototype. When developing a prototype, it is usually much faster to just write the SQL statements and put more focus on the UI and the user tasks (which are important). The next important step would be to add the building blocks to your application that are necessary to give it a reasonable chance of success in supporting new requirements. Unfortunately, this is not always done. It always fascinates me that although almost all applications have the initial requirement to support multiple databases, no initial thought is given to this requirement, in the interest of building the application quickly. The database-independent code is usually an afterthought. ACS 3.x (and earlier) contained embedded SQL. ACS 4 evolved into using named queries and provided APIs onto them, abstracting these APIs from the application code. OpenACS used this approach with its XQL query dispatcher. The approach involves extracting the queries out of the code, and then eliminating the application's need to know about column information. If the application has the queries extracted but still uses the column names, it becomes difficult (if not impossible) to rename columns, move columns from one table to another, or even remove columns. ACS5 now uses a full-fledged persistence layer to take database independence a huge step further. Object-relational persistence - what's that? JDBC example code fragment: Persistent Object example: This approach allows you to create objects that save and retrieve themselves from a database. This concept is more formally called Object to Relational Persistence. Using a persistence layer that provides objects based on your data offers several interesting capabilities. First, as an application developer, you can work with objects in more natural way. When dealing with a database, you would normally be thinking, "How do I save my Student data?" and then translating this into actual SQL calls. Working with Student objects eliminates the need to do the translation and frees you to do more meaningful application work instead of lower-level, error-prone, verbose code. The problem with persistent layers is based on the "impedence mismatch" between object hierarchies and the relational structure in a SQL database. These two types of structures do not naturally translate into one another. Despite the problems in the translation between the two, object persistence is gaining momentum. As a result, there are several commercial products on the market today. Some work, while others don't. Because the majority of the initial implementations were home grown and the earlier productized implementations of persistence were incomplete, a general perception exists that object-relational persistence layers don't work at all. This perception will not change until persistence layers mature and can be demonstrated to add value in the construction of software applications. It is interesting to note that SQL databases generated the same reaction when they were first developed. At the time, most applications were written in dBASE, Clipper, or FoxPro. Once SQL databases were demonstrated to be reliable and to perform well, applications were ported to use SQL databases such as ORACLE. Object-relational persistence requirements
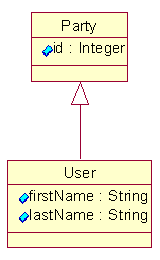
A persistence layer must support the concept of an object identifier so that objects can be uniquely identifiable for the purpose of retrieving and updating specific objects in the database. Inheritance must also be supported from a persistence perspective. The following example shows a User class inheriting from a Party class. Dealing with inheritance in object-relational persistence frameworks is most often implemented as joins between the tables used to store the Party data and the tables used to store the User data. One way to persist the class defined here is to create a Party table and a User table, where there is a foreign key from the User table to the Party table. Next, associations must be supported in order to retrieve objects that are related to one another. This is an area in which some persistence layers fall short. You should be able to retrieve objects from other objects without having to manage the relationship ids in your application code. To retrieve a related object, you should simply be able to ask for the related object by property name. If the object has not been retrieved, the persistence layer should get it for you. This mechanism should also handle lists of associated objects. When retrieving a list of associated objects, a persistence layer should not create object instances for every object in the list. Rather, it should provide some sort of list abstraction that only instantiates objects for the current element in the list if your code needs an object. Otherwise, the list should just encapsulate the data by using a resultset internally. This way, the code can get a list of objects and traverse the entire list to get the data, without the overhead of object instantiation. Similarly to using associations, your application code should be able to get a list of objects without starting from another object. An example is to get a list of all Users in a database rather than getting a list of Users from a Group object. This list also should take advantage of using a resultset internally to avoid unnecessary object instantiation. Additional features include support for multi-valued attributes and attributes on associations. Multi-valued attributes essentially allow you to define an array or a set of values for an attribute on a class. Also, when two objects are associated in some way, you may want to define attributes that apply to the association. For example, when you add an Employee object to a Department object, you may want to define a "startDate" attribute. This attribute means nothing in relation to the individual objects alone, but it has contextual meaning when applied to the association. The persistence layer requirements listed so far allow you to instantiate a single object (or list of objects) and traverse the relationships defined between these objects. However, in many cases, you need the additional support of arbitrarily querying a database for object data. This is where the impedence mismatch is brought to the forefront. Later, I will show how the persistence layer developed by ArsDigita handles this problem. At this point, note that this is a real requirement of a persistence layer. Without it, you will find yourself needing to use SQL in your application code, which obviates the benefit of a persistence layer. A good persistence layer must address concurrency and transactional management in order to ensure the ACID properties of the database. Objects must not arbitrarily overwrite data saved by other objects. This should be handled through the use of transactions and some sort of concurrency check internal to the persistence layer, to avoid overwriting data with stale object data. This means that objects need to detect whether data has changed since it was last retrieved before overwriting changes in the database. With any good persistence layer, metadata describing the persistent objects is useful for your application to dynamically take advantage of the persistence layer. For example, you could add attributes to a class, along with its mapping information. This additional property is then accessible by your application code. If your code uses the metadata for discovering the object's attributes at run time, the additional attributes can be consumed by the application. Based on the robustness of the mapping data provided by the persistence layer, a persistence layer should provide dynamic query support. This allows you to define where attribute data exists in the database and have the persistence layer figure everything out for you. Since this has inherent flaws, a good persistence layer should also support static SQL. This allows you to override SQL generated by the persistence layer, so that you can optimize the SQL as you see fit. Since a persistence layer abstracts away the database access into a usable set of classes, the obvious assumption is that a persistence layer must support multiple databases (such as Oracle, Postgres, SQL Server, etc.) without having to change any code. The requirements for a good persistence layer are not limited to the ones described here. Performance and scalability, for example, are also extremely important and were an important factor in the design of the ACS persistence layer. This article focuses specifically on requirements that make up the differentiating factors between persistence layers. Having chosen to use a persistence layer and reviewed the requirements, what's your next step? You can take a look at existing open-source persistence products such as Osage or Castor, or commercial products such as TopLink or ObjectSpark. Alternatively, you might implement your own, using standards such as EJB (Enterprise Java Beans) or JDO (Java Data Objects). ArsDigita has made the choice to implement a persistence layer as part of ACS in order to meet our requirements and the demands for a scalable web application. The driving factors for this decision include the ability to generate dynamic and support static SQL, attributes on associations (named "link attributes" in ACS), and full support for associations, including buffering data without unnecessarily instantiating objects for each row in the result. The ACS Persistence Layer
What does the persistence layer in ACS look like? Assume the following schema (ignoring Party data for simplicity): Schema create table users ( user_id integer not null constraint users_pk primary key, fname varchar2(100) lname varchar2(200) ); create table groups ( group_id integer not null constraint groups_pk primary key, name varchar2(100) ); create table group_member_map ( id integer not null constraint gmm_membership_id_pk primary key, group_id not null constraint gmm_group_id_fk references groups(group_id), member_id not null constraint gmm_member_id_fk references users(user_id), constraint gmm_group_member_un unique(group_id, member_id) ); Here is a UML model defining the persistent classes that can be mapped to the schema example.  UML Diagram To define your persistent objects, you must write a PDL file. A PDL file contains syntax for defining persistent objects specific to ACS. PDL allows you to define the persistent object types, their attributes, any mappings between attributes and columns, and the object events. Specific events are fired at run time for handing object persistence. For example, each object type has a retrieve, insert, update, delete, and a retrieve-all event that can be defined using static SQL or automatically generated by the persistence engine. Using the example schema and UML model, the following example demonstrates how to define a User persistent object in PDL, assuming the use of static SQL:
model com.arsdigita.foo;
// Define User persistent object
object type User {
// Define attributes of User
BigDecimal[1..1] id;
String firstName;
String lastName;
// Define which attributes make up the unique identifier of the User class
object key (id);
// Defines how to read a single user object from the database
retrieve {
do {
select users.user_id, users.fname, users.lname
from users
where users.user_id = :id
} map {
id = users.user_id;
firstName = users.fname;
lastName = users.lname;
}
}
// Defines how to insert a new user object into the database
insert {
super;
do {
insert into users
(user_id, fname, lname)
values
(:id, :firstName, :lastName)
}
}
// Defines how to update a user object in the database
update {
super;
do {
update users
set fname = :firstName,
lname = :lastName
where user_id = :id
}
}
// Defines how to delete a user object from the database
delete {
do {delete from users where user_id = :id}
super;
}
// Defines how to retrieve a list of user objects from the database. This
// this list can be filtered in application code.
retrieve all {
do {
select users.user_id, users.screen_name,
parties.uri, acs_objects.object_type
from users,
parties,
acs_objects
where parties.party_id = users.user_id
and acs_objects.object_id = parties.party_id
} map {
id = users.user_id;
screenName = users.screen_name;
uri = parties.uri;
objectType = acs_objects.object_type;
}
}
}
For each object type you define in PDL, you can specify certain events. These events are fired when you invoke specific methods in your code. For example, calling the save method on a persistent object will fire either the insert event or the update event for the object, depending on whether the object is new or already exists in the database. Calling the remove method on a persistent object calls the delete event. Within each event, you can specify the SQL that is executed for that event, or generate the events automatically. If you want the SQL statements to be generated automatically for the User object type, you define the following in PDL:
model com.arsdigita.foo;
// Define User persistent object
object type User {
// Define attributes of User
BigDecimal[1..1] id = users.user_id;
String firstName = users.fname;
String lastName = users.lname;
// Define which attributes make up the unique identifier of the User class
object key (id);
}
Based on these PDL definitions, all necessary events for the User are automatically generated by the persistence engine. As mentioned earlier in this article, associations are a critical piece of any persistence layer. The next example shows a defined User (from the previous example), a Group, and an association between User and Group.
model com.arsdigita.foo;
// Define User persistent object
object type User {
// Define attributes of User
BigDecimal[1..1] id = users.user_id;
String firstName = users.fname;
String lastName = users.lname;
// Define which attributes make up the unique identifier of the User class
object key (id);
}
// Define Group persistent object
object type Group {
// Define attributes of User
BigDecimal[1..1] id = groups.group_id;
String name = groups.name;
// Define which attributes make up the unique identifier of the Group class
object key (id);
}
association {
Group[0..n] groups;
User[0..n] members;
retrieve members {
do {
select users.user_id, users.fname, users.lname
from group_member_map, users
where group_member_map.group_id = :id
and groups.group_id = group_member_map.member_id
and acs_objects.object_id = parties.party_id
} map {
members.id = users.user_id;
members.screenName = users.screen_name;
members.uri = parties.uri;
members.objectType = acs_objects.object_type;
}
}
add members {
do {
insert into group_member_map
(id, group_id, member_id)
values
(acs_object_id_seq.nextval, :id, :members.id)
}
}
remove members {
do {
delete from group_member_map
where group_id = :id
and member_id=:members.id
}
}
clear members {
do {delete from group_member_map where group_id = :id}
}
retrieve groups {
do {
select groups.name,
parties.uri, acs_objects.object_type
from group_member_map,
groups,
parties,
acs_objects
where group_member_map.member_id = :id
and groups.group_id = group_member_map.group_id
and parties.party_id = groups.group_id
and acs_objects.object_id = parties.party_id
} map {
groups.id = groups.group_id;
groups.name = groups.name;
groups.uri = parties.uri;
groups.objectType = acs_objects.object_type;
}
}
add groups {
do {
insert into group_member_map
(id, group_id, member_id)
values
(acs_object_id_seq.nextval, :groups.id, :id)
}
}
remove groups {
do {
delete from group_member_map
where group_id = :groups.id
and member_id=:id
}
}
clear groups {
do {
delete from group_member_map where member_id = :id
}
}
}
The biggest problem with most persistence layers is that they don't provide a way to support querying the data through the object API. Here is where the object to relational impedence mismatch really becomes an issue. ACS supports queries in two ways. First, you can define named queries in PDL, which you can then use in your code. The benefit here is that you are not placing the queries in your code, so you can upgrade the queries as needed without recompiling your application. This is also very useful for optimizing queries, since you can optimize the query without changing your code. The following is an example of a named query in PDL:
query UsersAndGroups {
do {
select * from users u, groups g, group_member_map m
where u.user_id = m.member_id and m.group_id = g.group_id
} map {
userId = u.user_id;
groupId = g.group_id;
firstName = u.fname;
lastName = u.lname;
groupName = g.name;
}
}
The named query is usable in the following example:
DataQuery query = session.retrieveQuery("UsersAndGroups ");
while (query.next()) {
System.out.println(query.get("firstName") + query.get("lastName") + query.get("groupName"));
}
Second, you can choose to bypass the persistence layer and write raw JDBC calls. This is not the preferred method, but the option is always available if the persistence layer is not the best choice. Although this technique violates the concept of encapsulating a database, it allows developers to bypass aspects of the system if they find themselves too constrained. Our goal is to minimize the necessity of bypassing by providing compelling software to meet your needs. Now that the PDL defines the persistence for Users, Groups, and the association between User objects and Group objects, you can use the persistent objects in your code. Also, if you have any schema changes or enhancements, you can modify the PDL appropriately. This way, your code automatically receives the benefits of changes and can also start to use any additional attributes, for example. The following is an example of retrieving a Group object and then iterating through the list of Users for a Group:
DataObject group = session.retrieve(new OID("com.arsdigita.foo.Group", 1));
if ( group != null ) {
// get the collection of related objects as defined by the role "members"
DataAssociation users = (DataAssociation) group.get("members");
DataAssociationCursor cursor = users.getDataAssociationCursor();
while (cursor.next()) {
System.out.println( cursor.get("firstName")+ " " + cursor.get("lastName"));
}
}
For more information, see the ACS Persistence Documentation: Sun provided the EJB 1.1, which includes a specification for persistence - specifically, container-managed persistence (CMP) and bean-managed persistence (BMP). Unfortunately, the specification does not include support for object relationships. In addition, the specification assumes that the persistent objects are concrete Java classes. ACS requires persistent object types to be defined dynamically, including extending object attributes through metadata. EJB 1.1 does not appear to cover this in any way. Additionally, there is no standard way to query the object data without using JDBC directly. EJB 2.0 is almost finished but not yet released (as of August 22, 2001). It provides significant improvements over EJB 1.1, including support for relationships. In addition, EJB 2.0 introduces a new query language for retrieving data from a database in terms of object definitions. The object query is then translated into appropriate SQL. This relationship support and query support represent a huge step forward and will be investigated as ACS matures in the Java world. For now, certain factors prevent ACS from taking advantage of EJB 2.0. For example, since the specification is not yet released, no Application Servers exist that support EJB 2.0. It is therefore is unknown which ones they will be and how they relate to our targeted customers. These questions must be answered before ACS can support EJB. It is also important to note that ACS is built to support the development of web applications (that may use web services) and not necessarily to support a distributed object environment (for which EJB is ideal). In addition, ACS (being open source) should not require the purchase of a high-end Application Server as a result of supporting EJB 2.0. To that end, it will be interesting to see how and when products such as jBoss, OpenEJB, and Enhydra support EJB 2.0 (since these products are also open source). Java Data Objects (JDO) is another specification provided by Sun. JDO is meant to be used for defining the specific objects responsible for persisting data in an object fashion. Ideally, JDO would be used as part of the implementation of CMP in EJB. Currently, JDO is designed to support EJB 1.1. As a result, JDO suffers from EJB's missing pieces (such as the lack of object relationship support). There are two specific open-source persistence products that are worth mentioning, given that closed-source products are not an option. These are Castor and Osage. Osage is not an Enterprise tool and does not have locking or modification detection for protection against inadvertent overwrites. The Osage documentation recommends it only for smaller systems, which makes it less than ideal for ACS' needs. Castor is based on Osage and has an implementation of JDO (it does not strictly adhere to the JDO specification, though, as mentioned in their documentation). Although it has some interesting features, Castor does not appear to solve ACS' needs regarding link attributes and the ability to dynamically create persistent object types and attributes. Wrap up
Currently, we have some requirements that preclude us from adopting other persistence layers. These requirements are mostly but not limited to being able to support dynamic SQL as well as statically defined SQL and link attributes. In addition, ACS needs the ability to dynamically define persistent objects during run time to support features such as user-defined content items. The ACS persistence layer has become an integral part of the ACS kernel and is becoming an invaluable aspect of ACS. This work is the foundation from which we will be supporting other databases as we move forward. asj-editors@arsdigita.com
Related Links
|
|