Fault Tolerant Oracle Installationby Xuequn Xu (xux@arsdigita.com) Submitted on: 2000-06-03
ArsDigita : ArsDigita Systems Journal : One article
OPS offers transparent failover; the only thing a user would
notice in the event of a failure would be rollback of any transactions
in progress when the system failed. In addition to high availability,
OPS has benefits such as scalability and high performance. For less
critical services with smaller budgets, a standby database -- a second
computer that perpetually loads the production database's archived
redo logs -- is a good choice. Although human intervention is usually
needed to activate a standby database, guaranteeing a downtime of at
least a few minutes in a failure, it is a much less expensive option
and much easier to set up and maintain than OPS. In addition, in
Oracle8i, the standby database itself can be opened as a read-only
database for reporting.
Below, I will describe how to set up a standby database system and an
OPS installation for high availability. I will also take a close look
at the hardware necessary to run OPS and look at the costs and
benefits of some common hardware configurations. Finally, note that
are at least three ways other than OPS and standby database to make an
Oracle installation more reliable than a generic one-computer setup,
including Replication and OS-based methods. Thomas Kyte runs down the
pros and cons of all three, plus the two described above, in his
article "Oracle Availability Options" in Oracle Magazine (http://www.oracle.com/oramag/oracle/00-May/o30tom.html).
To understand how standby database works, we need to talk a little
about Oracle's log archiving mechanism. Any Oracle database operates
in one of two modes: NOARCHIVELOG or ARCHIVELOG. Redo logs are
re-used and re-written in a cyclic manner. In NOARCHIVELOG mode, the
redo log files are not archived before being re-used. If there are 3
redo log groups, and the log files are written to group 1, then group
2, then group 3, when the last group (group 3) is fully written the
database writes redo information to group 1 again, overwriting its
previous content. As a result, for a database operating in
NOARCHIVELOG mode, it can only "rescue" the amount of transactions
that are kept in the redo logs in case of instance failure. For a more
detailed description, see Oracle's online documentation "How Oracle
Keeps Records of Database Transactions" (http://oradoc.photo.net/ora816/server.816/a76993/intro.htm#422312).
In ARCHIVELOG mode, however, the redo logs are archived before they
are re-used, so a full history of the redo information is kept. This
allows open database backup (hot backup), time-based recovery (http://oradoc.photo.net/ora816/server.816/a76993/performi.htm#14678)
and more.
Standby database technology involves two databases on two separate
machines running in ARCHIVELOG mode. The production database archives
its redo logs into at least two destinations: its own storage,
and the standby machine's storage. These two machines should have a
good network connection because the archived redo logs are
transferred from the production database to the standby database through
Net8, Oracle's networking solution for distributed databases (http://oradoc.photo.net/ora816/network.816/a76933/toc.htm).
The standby database is running in ARCHIVELOG mode, too. In addition,
it is almost always in recovery status, with the database mounted but not
open, allowing the archived redo logs received from the production
database to be applied in a timely fashion. It is just like any
ARCHIVELOG mode database undergoing whole database recovery. The
Oracle8i Backup and Recovery Guide (http://oradoc.photo.net/ora816/server.816/a76993/toc.htm)
has more details on this. In short, if you have a good understanding
of how Oracle backup and recovery works in ARCHIVELOG mode, it is easy
to imagine the role of the standby database. It is like a "clone" of
the production database, but in constant recovery mode where redo
logs are applied to the database.
The standby database feature first appeared in Oracle7, mainly as a way to
quickly clone an existing database. In pre-8i releases, the archived
redo log from the production site needed to be transferred to the standby
machine manually, or through some automated methods implemented by the
database administrator. Its use in fail-over in a single
instance environment is greatly improved in Oracle8i, since the
archived redo logs are transferred automatically by the database to
the standby site through Net8. This is enabled by simply specifying a
connect descriptor as one of the archive destinations on the production
database's parameter file. A very good, step-by-step instruction on
how to implement such a standby database is in an Oracle Magazine article,
"Implementing an Automated Standby Database," by Roby Sherman
(http://www.oracle.com/oramag/oracle/99-May/39or8i.html).
An important point to remember is that before actually activating the
standby database, always try to get the failed production database's
redo log files, including: online redo logs that are not yet
archived, and those archived but not yet transferred to the standby
database. Try archiving the current online redo log by "ALTER
DATABASE ARCHIVE LOG CURRENT," which is not always possible since the
whole production machine may be down.
Normally a database is used by only one
instance. OPS uses multiple instances to mount the same database,
one on each of the nodes in a cluster.
Many machines can be involved,
but for the sole purpose of fault tolerant fail-over, usually two
machines (two instances) are used. In a two-instance OPS configured
for fail-over, only one of them (primary instance) accepts user
connections. Once the primary instance fails, the
secondary instance takes over. OPS
makes zero down time a reality, because the database service
will never fail and the data is consistently available.
Only the transactions being performed at the failed node need to be
resubmitted.
The most comprehensive documentation on all aspects of OPS is Oracle's
online books, and there are three in Oracle8i dedicated to OPS:
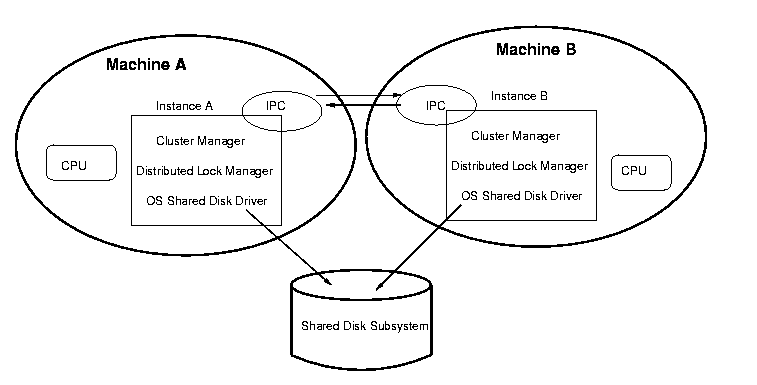
From the hardware side, OPS must have two or more computers linked
together by an interconnect, and in order for those computers to
share files they must have access to a shared disk subsystem (http://oradoc.photo.net/ora816/paraserv.816/a76968/pshwarch.htm#4270).
This
is normally implemented through uniform disk access
for SMP systems
and non-uniform disk access
for MPP systems.
The server software of the OPS architecture has these components:
Since OPS operates on a single set of datafiles, storage device
failure could be disastrous even if there is not instance
failure at the individual nodes. Hardware based mirroring is often used
to maintain redundant media.
On the client side, the switch of connection to the secondary instance
in case of primary instance failure is achieved through Transparent
Application Failover (TAF) (http://oradoc.photo.net/ora816/paraserv.816/a76934/chap5.htm).
The configuration is written into the tnsnames.ora file, which is used
by the client to resolve a database connection descriptor (service
name). For example:
On the server side, the listener.ora file needs to be changed so that the
Oracle listener obtains database instance information through dynamic
service registration (http://oradoc.photo.net/ora816/paraserv.816/a76934/glos.htm#1000215).
This is done by simply removing the "SID_LIST_<listener_name>"
section of the file. More details of configuring OPS
high-availability features can be found from Oracle8i's online
documentation (http://oradoc.photo.net/ora816/paraserv.816/a76934/chap5.htm#596946).
For more information on Net8 configurations, read "Oracle8i Net8
Administrator's Guide" (http://oradoc.photo.net/ora816/network.816/a76933/toc.htm).
On the software side, Oracle Enterprise Edition with Parallel Server
Option is certainly needed (Parallel Server Option is licensed
separately). Solaris 2.6 or 8 is needed on each of the two nodes, as
well as Sun Cluster software licensed for each node. According to Sun
customer service, Oracle 8.1.5 OPS is not supported in Solaris 8. The
Cluster Volume Manager required for OPS is included in Sun Cluster
software.
Calculating the cost of the software licensing in OPS can be
tricky. For example, let's say you want to set up two-node OPS for
high availability, and each computer has two 450 MHz processors. The
"Universal Power Unit" (UPU, Oracle's way to determine the power of
your system) is 1,800 (2 computers x 2 processors of each computer x
450 Mhz). Divide that by 30 (one named user license covers 30 UPU),
and the number of licenses you need to buy is 60. From Oracle's online
store, the "perpetual" price for Oracle8i Enterprise Edition is $750
per licensing unit, for the two-node system $45,000 is needed just for
Oracle8i database server. The Parallel Server Option will add an extra
$18,000 ($300 for each licensing unit), and the total is
$63,000. Depending on how powerful the computers are in the parallel
system, plan on around $100,000 for the Oracle software. The Sun
Cluster software and operating systems will likely take another
$100,000.
The hardware prices are also highly variable depending
on actual configurations. OPS runs on a wide range of hardware. In the
Solaris systems, one low-end 220R costs under $10,000, while the very
high-end Enterprise 10000 server can go above $1,000,000. The
"mid-range" Enterprise 4500 is $223,000 (list price as of May 2000).
Also keep in mind that the more powerful the hardware, the higher the
licensing charge for Oracle server software (as described above).
The costs of disk arrays vary on size and speed. A Netra st A1000/D1000
disk array (provides 36-216 GB) costs around $15,000, while an A3500
disk array (1,092 GB and up) is around $200,000. In short, plan on a
total investment of $500,000 - $1,000,000 for a two-node OPS system, using
mid-range Sun hardware. It is also possible to implement OPS on
Windows NT systems. People have gotten it done at around $250,000,
but it is not as stable and reliable.
There is an interesting post recently to the USENET newsgroup comp.database.oracle.server, and I
think it provides an excellent case of OPS (plus standby database) in the real world. The conclusions:
Admittedly, my experience on the matter comes from a project to implement a dual Sun E10000 project with Solaris 2.6 and Oracle 7.3. We ended up using only one node, with the other one as a standby, something that could also be done cheaper with an active/standby cluster configuration (if we were prepared to have downtime equivalent to a database recovery operation). On the plus side, the system did meet the high level of availability and near-instant failover. You should also be aware that OPS imposes significant constraints on what can or cannot be done in terms of administration or database features, and requires DBA of the very highest caliber to run correctly. OPS has improved with Oracle 8, and it is now capable of running with the same performance as a single server setup as long as all write transactions are performed against a single node (but reads can be spread among the others). Moral: OPS is a good solution for databases needing superlative levels of availability. If performance or operational costs are an issue, you should think hard about a "simple" active/standby clustering solution. If you are still considering OPS, you should at the very least ask Oracle to let you visit some of their reference clients, and secure consultants who have had operational experience in deploying OPS.
|
|